In eerdere delen van de reeks ging het vooral over doel, gebied, de vraag wat een KPI is en de vraag of het om product en/of productieapparaat gaat. In dit deel staat de vraag centraal waar een datamodel in de sector en in de keten thuishoort, omdat precies daar later het verschil ontstaat tussen bruikbare ordening en bestuurlijke ontsporing.
In dit schrijven wil ik jullie aan de hand van zo’n voorbeeld meenemen langs de vraag wie de belanghebbenden zijn, wie welke verantwoording draagt en welke stakeholders daarbij horen. Daarna komen taken en verantwoordelijkheden aan bod. Ook komt aanbod wie in de keten de kosten op zich neemt. Als laatste vat ik het samen hoe het volgens mij zou moeten zijn en zou kunnen starten.
De kernvraag is niet wie de data handig kan gebruiken, maar wie eigenaar is, wie beheert en wie verantwoordelijk is voor welk deel van dat beheer. Aan het einde van dit stuk moet voor jou duidelijk zijn wie de data niet alleen gebruikt, maar ook hoort te beheren en te mogen delen.
Stakeholders
Om dit vraagstuk bestuurbaar te maken, moet eerst scherp zijn wie hier niet alleen meepraat, maar ook bevoegd is, verantwoordelijk is en toegang tot data mag hebben.
- Producent
- Eigenaar productie apparaat
- Data beheerder
- Klant(en)
- Klant voor product; van Verwerker tot aan eind Consument
- Productieapparaat > Wet en Regelgeving, de overheidslagen
Onderscheid in verantwoordelijkheden
- Invoer en aanlevering van data: de producent van het product en de eigenaar/gebruiker van het productieapparaat zijn daarvoor verantwoordelijk. (Vaak zie je in de praktijk dat verantwoording nemen van productie apparaat door eigenaren van apparaat bij de gebruiker van apparaat, lees producent gelegd worden juist voor het deel van wet- en regelgeving vanuit overheidslagen). 1 en 2
- Databeheer is de verantwoordelijkheid van de juridische entiteit die de data, na toestemming en op basis van een getekende overeenkomst, in bewaring heeft gekregen. 3 en 1
- Delen van data gebeurt door Data beheerder (C) in opdracht van A richting D. 1 ,2 en 4
- Eigenaren van productieapparaat kunnen ook zelf een databeheerder inschakelen voor hun verantwoording als eigenaar richting de route D(b): klantvragen over het productieapparaat en vragen vanuit wet- en regelgeving. 2, 3, en 4 productieapparaat
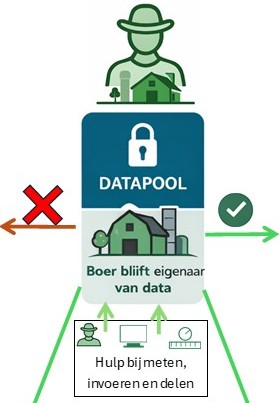
Datapool
Hieruit wordt al zichtbaar dat de data in de huidige waardeketen van product en productieapparaat door geen enkele partij in haar geheel beheerd kan worden. Dat leidt tot dubbele petten en tot onjuiste toegang tot, of inzage in, concurrentiegevoelige data.
De valkuil van bijv. melkveehouders is dat ze vaak maar aan één klant hun product melk leveren. Dat moeten we wel als de uitzondering blijven zien en niet de regel. Met het oog op de toekomst moet je nu juist een uitvoerbaarheid optuigen waarbij een producent aan meerdere klanten kan verkopen. De eerste eenvoudige stap kan al zijn dat een producent meerdere stallen bezit met gronden in verschillende ‘gebieden’. De melk van stal x kan naar klant FC gaan en de melk van stal z naar klant AW.
In andere takken van sport gaat dit al minder vanzelf via één vaste lijn. Akkerbouwers hebben verschillende producten met verschillende afzetkanalen. Ook in andere sectoren kan afzet lopen via meer dan één route, direct of indirect. Voor de opzet van een datapool is dit geen detail, maar het ontwerpuitgangspunt. Je moet dus niet bouwen vanuit de huidige praktijk waarin één producent vaak aan één klant levert, maar vanuit de mogelijkheid dat één bedrijf meerdere producten, stallen, percelen, batches en klanten heeft. Dan is ook direct duidelijk dat de relevante data niet altijd op bedrijfsniveau ligt, maar vaak lager: per locatie, per perceel, per stal of per batch.
Klanten hebben vragen over het product van de producent en over het gebruikte productieapparaat.
Is dan het bedrijf de producent, of is juist de productie op die locatie, met deze kengetallen en foodprint, relevant als antwoord op de klantvraag?
Voor product wordt al inzichtelijk dat het dus om data per batch kan zijn. Denk aan het eerder in de reeks benoemde productpaspoort. Voorbeeld: Waar is deze ui geteeld en hoe vaak is die met wat bespoten? Met hoeveel water zijn die uien op dat perceel beregend? Wat is de LCA, de food print van die ui? Hoeveel kunstmest bemesting heeft die ui gehad? Die gegevens wil je daarom op het laagst relevante niveau registreren, zodat je ze netjes en juist kunt delen met de juiste klant langs de product-as.
Waar staat de Datapool?
Daarmee hoort ook duidelijk te zijn dat deze datapool niet bij de klant en evenmin bij de producent kan worden ondergebracht. Geen van de ketenpartijen in de keten van product kan dit in zijn geheel op zich nemen.
Niet voor niets bestaan er organisaties als GS1 en datamodellen per branche. Landbouw hoeft hier ook niet het gehele wiel uit te vinden.
Landbouw is in dit vraagstuk juist uniek, omdat het hier veel meer over productieapparaat gaat dan alleen over product. Alle reden om beide direct goed uit de startblokken te laten komen om zo voor de komende 30 jaar een basis te hebben naar eer en geweten waarin en waarop kan worden voortgebouwd.
Waar staat de Datapool?
Daarmee hoort ook duidelijk te zijn dat deze datapool niet bij de klant en evenmin bij de producent kan worden ondergebracht. Geen van de ketenpartijen in de keten van product kan dit in zijn geheel op zich nemen.
Niet voor niets bestaan er organisaties als GS1 en datamodellen per branche. Landbouw hoeft hier ook niet het gehele wiel uit te vinden.
Landbouw is in dit vraagstuk juist uniek, omdat het hier veel meer over productieapparaat gaat dan alleen over product. Alle reden om beide direct goed uit de startblokken te laten komen om zo voor de komende 30 jaar een basis te hebben naar eer en geweten waarin en waarop kan worden voortgebouwd.
Wie betaalt de data?
Simpelweg is dat antwoord: de verkoper, de producent. Die wil wat en vraagt vervolgens een prijs voor zijn product. De producent, verkoper biedt waarde aan.
De waarde zit in 3 zaken:
- borging wet en regelgeving
- prestaties in productie apparaat
- prestaties product, USP’s > Unieke Selling (verkoop) Punten.
Op die drie pijlers rusten prijsafspraken en veel keurmerken. Met elkaar in de keten van bijv. een keurmerk maak je afspraken wie welk deel betaalt.
Duidelijkheid voor alles?
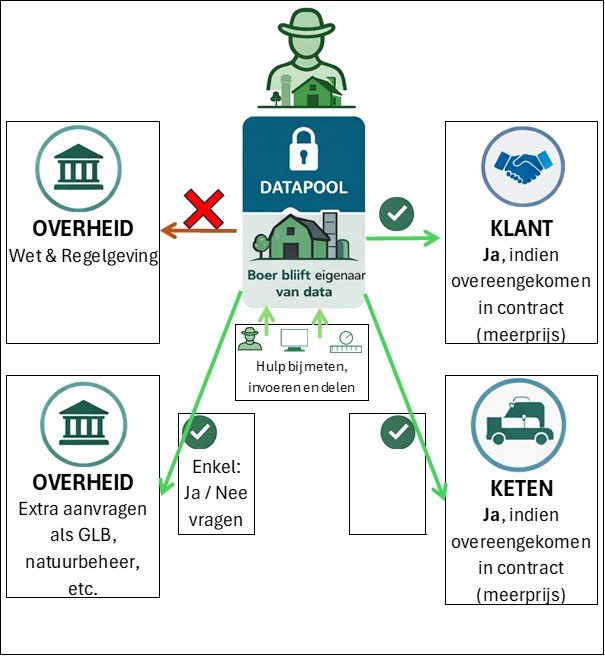
Wet- en regelgeving vraagt in de kern maar één ding: voldoet u wel of niet. Voor die vraag hoeft de overheid dus niet alle onderliggende data te krijgen. Het uitgangspunt moet zijn dat vanuit deze datapool alleen het hoogst noodzakelijke richting overheid gaat, bij voorkeur in Ja/Nee-vorm.
Ook bij beloningsvraagstukken blijft dat uitgangspunt overeind. Wie extra beloond wil worden voor extra inspanningen, zal moeten laten zien waarom die beloning terecht is. Maar ook dan hoeft niet automatisch alle detaildata naar de overheid. Denk bijvoorbeeld aan GLB-premie voor de melkveehouderij. De ondernemer mag zelf best weten of hij net geen A (goud) scoorde of gewoon een stabiele B had. Voor de overheid is die fijnmazige onderliggende score lang niet altijd nodig. Die hoeft in zo’n geval alleen te weten of het bedrijf wel of niet in de beloonbare categorie valt:
Brons: Ja
Zilver: Ja
Goud: Nee.
Juist daar hoort de grens te worden getrokken tussen informatie die voor het doel nodig is en informatie die daar niets te zoeken heeft.
De brondata zelf hoort daarom in de datapool te blijven, bij de brondata-eigenaar en onder beheer van de aangewezen beheerder. Daarmee voorkom je dat de overheid onnodig veel gegevens verzamelt die later kunnen leiden tot openbaarheid, verkeerde prikkels of ongewenste inzage in concurrentiegevoelige informatie.
Dat is ook de reden waarom bestaande registraties, zoals de Gecombineerde Opgave of I&R, bij de start bewust naast deze datapool moeten blijven bestaan. Een snelle koppeling lijkt aantrekkelijk, maar vertrouwen, rolzuiverheid en bescherming van de ondernemer wegen zwaarder dan de eerste quick win.
Pas in een latere fase kun je bekijken of koppelingen wenselijk zijn. Maar ook dan moet deze datapool geen verplichting worden. Het moet een ondernemerskeuze blijven. De kracht van het model zit juist in vrijwillige meerwaarde voor de ondernemer, de keten en de klant en niet in een nieuwe verplichte overheidsroute.
Samenvattend volgens Jeroen van VBCA
De beoogde datapool voor KPI’s komt er vóór de boer, van de boer: het landbouwbedrijf zelf. De datapool is er voor harmonisatie in de keten en verkoopafspraken met klanten. Zo helpt uniformering om data efficiënter te delen met meerdere klanten en tegelijk bedrijfsmatige vooruitgang te boeken. Het geeft bedrijven inzicht om beter te worden op onderdelen en dieper inzicht te krijgen wat hun huidige positie is per dier/perceel, zeg maar detail van detail.
De overheid krijgt enkel en alleen informatie die nodig is voor reeds geldende wet- en regelgeving, en dan bij voorkeur in Ja / Nee -vorm. Voor beloningsvraagstukken kan dat binnen deze datapool plaatsvinden, maar voor de basis van wet- en regelgeving blijft die route bij voorkeur uit voorzorg 100% gescheiden van deze datapool.
Na livegang kan het een ondernemerskeuze worden om het ook vanuit deze datapool te gaan doen. Nimmer kan dat de verplichting en/of enige route worden.Wie in de keten werkt aan datastandaarden, beloningssystemen of bijvoorbeeld true value-benaderingen, doet er verstandig aan deze governance vraag eerst goed te beantwoorden. Anders loopt het model later alsnog vast op rolvermenging, verkeerde datatoegang en gebrek aan vertrouwen bij de ondernemer.
Kamerbrief van minister Jaimi van Essen
Vraag aan de minister n.a.v. zijn Kamerbrief: Samenhangende aanpak Landbouw, Natuur en Stikstof van 27 maart jongstleden: Is dit en hoe is dit geborgd in uw taskforce?
Welke experts zitten hiervoor aan tafel in welke rol en met welke kennis van zaken?
Jeroen van Buuren | Van Buuren Continuum Advisory (VBCA)
Adviseur op het snijvlak van systeemvraagstukken, landbouw en beleid.
In deze reeks werk ik stap voor stap uit waar doelsturing en KPI’s op papier helder lijken, maar in praktijk en uitvoering gaan wringen.
Contact: jeroen@vbca-org.nl
Meld je hier aan voor nieuwe delen in deze reeks.
Dit artikel verscheen in een reeks: Doelsturing en KPI’s